


Editor’s note: Wayne Yaddow is an independent consultant with over 20 years’ experience leading data migration/integration/ETL testing projects at organizations including J.P. Morgan Chase, Credit Suisse, Standard and Poor’s, AIG, Oppenheimer Funds, IBM, and Achieve3000. Additionally, Wayne has taught IIST (International Institute of Software Testing) courses on data warehouse, ETL, and data integration testing. He continues to lead numerous ETL testing and coaching projects on a consulting basis. You can contact him at wyaddow@gmail.com.
Introduction to Data Quality Risk Assessments
Data warehouse and business intelligence (DWH/BI) projects are showered with risks — from data quality in the warehouse to analytic values in BI reports. If not addressed properly, data quality risks, in particular, can bring entire projects to a halt—leaving planners scrambling for cover, sponsors looking for remedies, and budgets wiped out.
Risk analysis is the conversion of risk assessment data into risk decision-making information. Risks are composed of two factors: (1) risk probability and (2) risk impact — the impact to the schedule of the DWH/BI project can also measure the loss by a risk.
Data quality risk management is a structured approach for the identification, assessment, and prioritization of data quality risks followed by planning of resources to minimize, monitor, and control the probability and impact of undesirable events.
Users don’t often know exactly what they want delivered until they start seeing early versions of the BI application (e.g., reports). This circumstance often requires BI teams to build the data warehouse and application reports before they are fully defined and specified. Couple this challenge with the data quality problems inherent when sourcing operational systems, scalability in terms of data volumes, data refresh rates, and the potential for risks are very real.
This blog outlines methods for recognizing and minimizing the data quality risks often associated with DWH/BI projects. Addressing additional DWH/BI project risks (including performance, schedules, defects discovered late in the SDLC, etc.) is also important, but is beyond the scope of this blog.
Data Quality is the desired state where an organization’s data assets reflect the following attributes:
- Clear definition or meaning
- Correct values in sources, during extraction, while loading to targets, and in analytic reports
- Understandable presentation format in analytic applications
- Usefulness in supporting targeted business processes.
Figure 1 illustrates primary control points (testing points) in an end-to-end data quality auditing and reporting process.
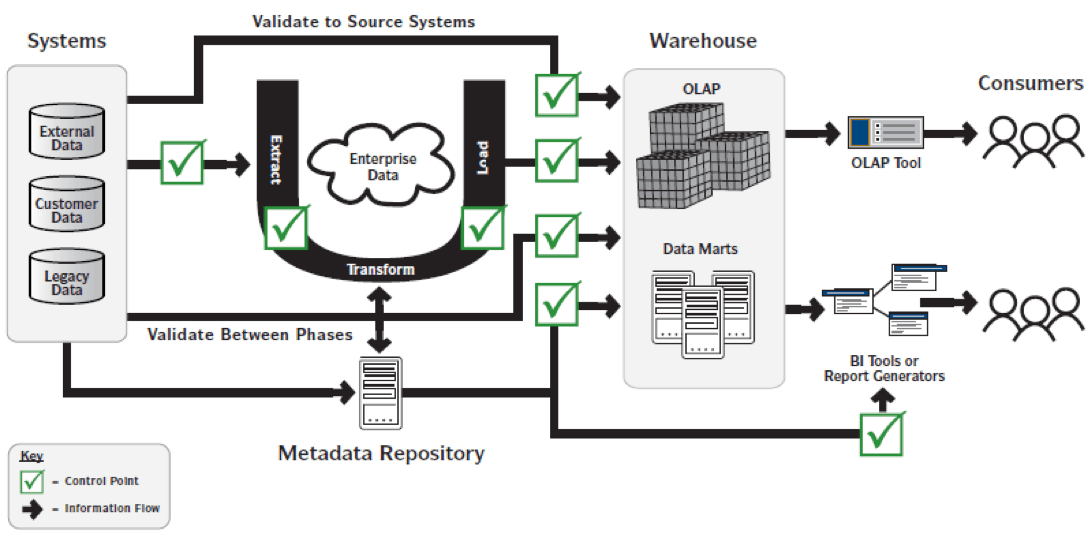
Data Quality Risks Should be Addressed Early and Often
The extraction, transformation and loading (ETL) process is still the most underestimated, under-budgeted part of most BI/DW iterations. And the biggest reason why the ETL portion of a project often raises more questions than it resolves has to do with a lack of understanding of the source data quality. [Data Warehouse Testing, ETL Testing, and BI Testing: What’s the Difference?]
The following are common data quality risks with the probability/odds that they exist as well as their possible impacts. The listing is not intended to be exhaustive; please note we show only those known to frequently be of “high” impact to the BI project.
| Data Quality Risk | Odds | Impact | Potential Risk Mitigation Tasks |
| HUMAN RESOURCE SKILLS Insufficiently qualified resources with required knowledge of data warehouse and business intelligence testing; lack of skills with data testing toolsets, methods and best practices. | Med | High | Engage DWH/BI training resources, recruit staff with DW experience, contract DWH/BI professional consultants.
|
| MASTER TEST PLAN/STRATEGY A master test plan/strategy does not exist or is inadequate in scope | Med | High | The Test Strategy / Master Test Plan documents the overall structure and objectives of all project testing— from unit testing to component to system and performance tests. It covers activities over the DWH/BI lifecycle and identifies evaluation criteria for the testers.
|
| SOURCE DATA QUALITY IN DOUBT Data integration effort may not meet the planned schedule because the quality of source data is unknown | High | High | Formal data profiling of all source data early (i.e., during requirements gathering) to understand whether data quality meets project needs. Inaccuracies, omissions, cleanliness, and inconsistencies in the source data should be identified and resolved before or during the extract / transform process. Often, specific data elements exist on multiple source systems. Identify the various sources and discuss with the users which one is most applicable. Use of commercial data quality tools accompanied by consultation and training. |
| SOURCE DATA HISTORY INCOMPLETE Differing levels of historical data among all source data | High | High | What if your business requirement calls for four years of historical data, but the best, most recent data contains only one year for some sources and three years for other sources? The three years would need to be extracted from other data sources, possibly of questionable quality.
|
| SOURCE & TARGET DATA MAPS SUSPECT Source data may be inaccurately mapped due to absence of data dictionaries and data models | Med | High | Data dictionaries should be developed and maintained to support all data associated with the project. Quality data mapping documents may be the result.
|
| TARGET DATA IN ERROR Only a subset of the loaded data could be tested | Med | High | -Ensure that the target data sampling process is high quality -Use test tools that allow for extensive data coverage -Choose a data sampling approach that’s extensive enough to avoid missing defects in both source and target data -Choose an appropriate technology to match source and target data to determine whether both source and target are equal or target data has been transformed -Verify that no data or information is lost during ETL processes. The data warehouse must get all relevant data from the source application into the target according to business rules. |
| SRC – TRGT END TO END TESTING UNCOORDINATED Poor or non-existent testing of source to warehouse data flows | High | High | This “auditability” must include validation that the information in a source system (such as a spreadsheet) is accurate so that there is a high level of confidence that it can be trusted when it’s loaded to the warehouse. IT organizations that perform only quality checks on data at a sub-set of points in the warehouse will probably fail to adequately protect themselves from the data quality problems that emerge when information is exchanged between all of these “dynamic points.” |
| Data Dictionaries and data models DEFICIENT Data and information within warehouse and/or marts cannot be easily interpreted by developers and QA | Med | High | -Ensure accurate and current documentation of data models and mapping documents. -Use automated documentation tools -Create meaningful documentation of data definitions and data descriptions in a data dictionary -Create procedures for maintaining documentation in line with changes to the source systems -Provide training to QA team by data stewards/owners |
| EXCESSIVE DATA DEFECTS Data defects are found at the late stage of each iteration | High | High | -Ensure that data requirements are complete and that data dictionaries are available and current -Profile all data sources and target sources after each ETL -Ensure that data mapping and all other specification documents are kept current |
| COMPLEX DATA TRANSFORMATIONS Complex data transformations and BI reports | High | High | -Early validation of table join complexity, queries and resulting business reports -Validation and clarification of business requirements, as well as early and careful translation of the data requirements -Validation of the number and accessibility of source data fields -Validation of the number of reports—get a sense of the number of existing reports that will be replaced as well as how many new reports will |
| DATA VOLUME SCALABILITY IN DOUBT Growing data volumes due to changing requirements | Med | High | -Employ toolsets for data volume estimations -Consider technical design for data volumes to be done by experienced DBA/data architects |
| DATA REQUIREMENTS INCOMPLETE Quality issues due to unclear or non-existent data requirements documentation. | Med | High | -Ensure that requirements are always updated after change requests are approved. -Perform validation and clarification of requirements, as well as early and careful translations of the data requirements |
| REGRESSION TESTS NOT AUTOMATED Minimal automation of regression tests | Med | High | Without automated regression tests, fewer tests may be run after build are deployed; manual testing may result in fewer tests being run
|
More potential data quality risks to consider:
- Legacy data architecture and data definition artifacts may be unavailable or incomplete to aid in project planning. Source data may be inaccurately mapped due to lack of (or outdated) legacy system data dictionary.
- The project team may encounter incompatible software, hardware, and/or processes due to multiple operating systems or vendors, or format incompatibilities (Database Management System (DBMS) to DBMS, DBMS to Operating System, etc.)
- The integrity and quality of the converted data may be compromised due to lack of enterprise-wide data governance.
- Independent data validation, the quality of the target system data may not meet the departmental standards because independent data validation (e.g., QA department, off-shoring) was not considered part of the scope of work.
- Source data may be inaccurately transformed and migrated due to lack of involvement of key business subject matter experts in the requirements and business rule process.
Common Conditions that Lead to Data Quality Risks
When business intelligence and analytics users are not seeing value in reports from the data warehouse, they are either experiencing bad data or bad analytics. Usually, it’s the data. Functional DWH/BI tests often seek out “bugs” in the ETL logic. That may be legitimate, but if the transforms are extracting defective sources, they are going to transform data into defective target results.
University researchers have found that the amount of data and information acquired by companies has close to tripled in the past four years, while an estimated 10 to 30 percent of it may be categorized as being of “poor quality” (e.g., inaccurate, inconsistent, poorly formatted, entered incorrectly). Common problems with enterprise data are many, but typically they fall into the following five major areas:
- Data Definitions – typically manifesting itself through inconsistent definitions within a company’s corporate infrastructure without supporting data dictionaries.
- Initial Data Entry – caused by incorrect values entered into corporate databases, inappropriate training and/or monitoring of data input, poor data input templates, poor (or nonexistent) edits/proofs of data values; etc.
- Decay – causing the data to become inaccurate over time (e.g., customer contact info, asset values, sales/purchase volumes).
- Data Movement – caused by inadequate or poorly designed ETL processes, can result in data warehouses which are comprised of more inaccurate information than the original legacy sources.
- Data Use – an incorrect application of data to specific information objects, such as spreadsheets, queries, reports, portals, etc.
Each of the above conditions represent a potential data quality risk to most DWH/BI projects.
The following project tasks should each have strong review, verification, or validation responsibilities associated with them to enhance data quality management through any data warehouse project:
- Business requirements collection and analysis
- Logical data modeling
- Data mapping
- Physical modeling and implementation
- Extraction, transformation, and loading (ETL) design
- Report and cube design
- Project planning
- Data quality management
- Testing and validation
- Data warehouse archiving
- Backup and recovery of the data warehouse
- Change management
- ROI determination
Concluding Remarks
Data warehouse projects are highly complex and inherently risky. It is the responsibility of the project manager to lead the data warehouse team to identify all data quality risks associated with a particular data warehouse implementation. The goal of this process is to document essential information relating to project risk.
If the project team and its designers fail to assess the quality of source data, then they are exposing the entire project to great risk. Consider this carefully: if no one takes time to assess all source data quality, then it is entirely possible that you will purchase and install all the DWH/BI technology, do all the analysis, write all the source-to-target code to populate target tables, and still fail.
[Read more data warehouse / BI testing blogs by Wayne Yaddow]