

Things that are easy to do are easier to expect people to take up and make part of their process. Obviously. . . . But think about that for a minute in the context of all the DevOps tools and technologies. If you make it easy to do something right (e.g., provide templates, good practices instructions, and informed process guardrails, as so many SREs do for product teams) and hard to do the wrong thing, you’re likely to improve software quality far more than expecting someone who’s already too busy to become an expert in performance overnight.
Particularly for a topic like performance testing, “easier is likely better” goes not only for test scripting but also for automating processes and infrastructure requirements, and for consuming the results of testing. Many Tricentis NeoLoad customers are now providing their product teams “self-service” resources and training in order to scale the performance mindset beyond a small band of subject matter experts (SMEs). Those SMEs are then able to apply their expertise to PI planning, process automation, and DevOps teams who need more help than others.
The modern mantra: early, often, and easy
Feedback loops for performance are a critical step for modern continuous delivery practices. In a nutshell, late-stage performance fixes are too costly to do anyone good and there are a few elements that need to be in place to expect to get performance feedback early in development cycles. Automation is key, but so is prioritizing which areas of architecture to “left shift” performance testing into.
Prioritization is at the heart of what’s often missing with the statement “early and often.” That’s why I tend to include “easy” to the list to remind us that, if we have picked a path that includes high resistance, we’re likely to fail. By “easy,” I don’t necessarily mean the path that is perceived as least complex; I mean easy in the project management sense of low hanging fruit or obvious to business owners — in other words, “easy to agree upon, easy to see the importance of.” It’s a lot easier to make a case for performance testing systems in the critical path than services that are far removed from what others think is important.
Prioritize, then systematize
One book that every performance-minded engineer should read is System Performance: Enterprise and the Cloud by Brendan Gregg, wherein he provides useful mental models such as Utilization-Saturation- Errors (USE) for system analysis. If we adapt this method to help us prioritize which systems under test (SuT) for which to automate performance feedback loops, it would look something like this:
- Utilization Which core APIs or microservices are at the nexus of many other business processes, thereby ballooning their usage as a shared enterprise architecture component?
- Saturation Which services have experienced “overflow” — the need for additional VMs/costs to horizontally scale — or are constantly causing SEV-n incidents that require “all hands on deck” to get back into reasonable operational status?
- Errors From a perspective of “process error,” how many times has a specific service update or patch been held up by long-cycle performance reviews? Which systems do we need fast time-to-deploy or where slow feedback cycles cause the product teams to slip their delivery deadlines (immediate or planned)?
Often, examples that rank high on one or more of these vectors include user/consumer authentication, cart checkout, claims processing, etc.
Other ways to view system performance, such as rate-error-duration (RED) signals and looking towards business metrics in analytics platforms, ensure that critical path and revenue-generating user experiences are working as expected.
Organizations that efficiently prioritize performance work look to these and other signals from both pre-production and in-production systems to see where to apply more of their efforts. Everyone now has some form of microservice architecture in play along with traditionally monolithic and shared systems, but not everyone realizes the benefits of independently testing and monitoring subsystems and distributed components in a prioritized and systematic fashion.
Easy scripting: why are APIs “easier”… and easier than what?
Modern APIs typically use standards such as HTTP and JSON to send and receive data. Often API teams also have a manifest of the REST API as described by an API specification, such as OpenAPI, Swagger, or WSDL documents. Additionally, test data is often more straightforward to inject since the payloads are often self-descriptive (i.e., field names and data match formats in examples). Finally, organizations with APIs often have functional test assets, such as in Postman or REST Assured test suites, which provide a reference point for constructing performance test scripts.
Dealing with API endpoints and payloads is often far less complicated than dealing with complete traffic captures of end-to-end web applications, which often include dynamic scripts, static content, “front-end” API calls only and other client-side tokenization semantics. API endpoints described in specification docs make scripting and playing tests back a far simpler proposition than ever before, rendering them as “easy” targets for early testing. Service descriptors also make it far easier to mock out APIs than entire web servers for end-to-end app tests . . . just look to the Mockiato project for examples of how it doesn’t take a genius or the rich to do service virtualization.
In NeoLoad, both OpenAPI and WSDL descriptors can be imported to quickly create load test paths, which can be further customized with dynamic data, text validations, and SLAs. NeoLoad also supports YAML-defined test details, which further simplifies “easy” load test suite generation. Once tests are defined, tests can be executed as part of a CI orchestration or pipeline, producing test results and SLA indicators as “feedback” information in early development cycles.
Easy pipelines: beyond the test script and into “codified process”
Everything is code now. Apps and services are code. Testing is code. Infrastructure is code (IaC). Networking is code. Security is code. Even compliance is code. And, yes, most if not all of these processes are also representable as code. Why has this happened?
Code is executable by a machine. It’s a representation of what you want to happen, whether you’re there to press the button to do it or not. It can be scheduled, triggered, and replayed. Code in a repository represents transparency, whether open source or closed source. Those that can read the code can understand what it’s doing and, when it’s not working, potentially see why. Code can be versioned, rolled back and forward, audited, and revised.
Test assets, testing infrastructure, and testing process, when represented as code, inherit all of these affinities. Most of the coding world has unified around Git (in one flavor or another) as the default version management protocol over all code assets. This allows performance testing tools like NeoLoad, Keptn, and a million other technologies to allow their artifacts to be maintained in an approved and understood system of control.
Many Tricentis customers not only store their test suites in Git but also store their “performance pipeline” scripts in the same repos as their load test projects. Why? Because changes to test scripts, testing semantics, and test data sources all usually predicate incorporation into the semantics of their process as code (a.k.a. the pipeline scripts). These changes can be done in a separate branch from the primary/master branch already approved and used by teams, then that branch can be run as the pipeline and proven to be working in order for promotion back to the master/trunk. Just like test case promotion, testing process promotion is critical to keeping the delivery process running smoothly and on time.
“Performance pipelines” are also often separate, triggerable processes from broader delivery pipelines. Why? When you run a performance test and it fails, you don’t necessarily need to rerun build, package, and deploy predicating steps; rather, operational configuration and deployment tweaks are often good enough to achieve optimal performance. After these changes are made, simply re-running the performance testing pipeline is a trivial task.
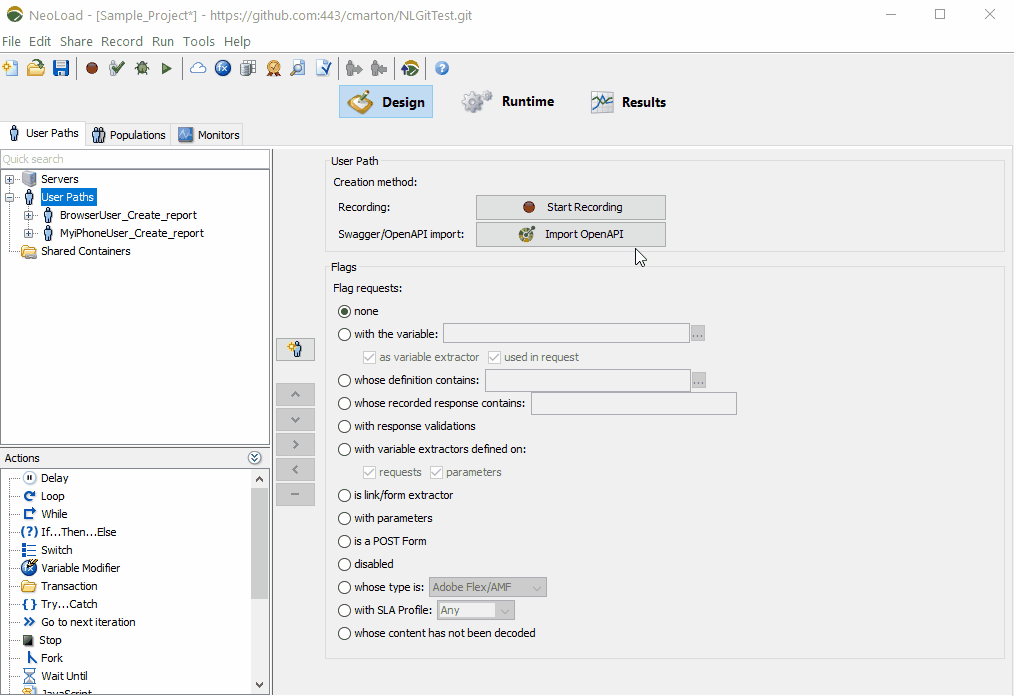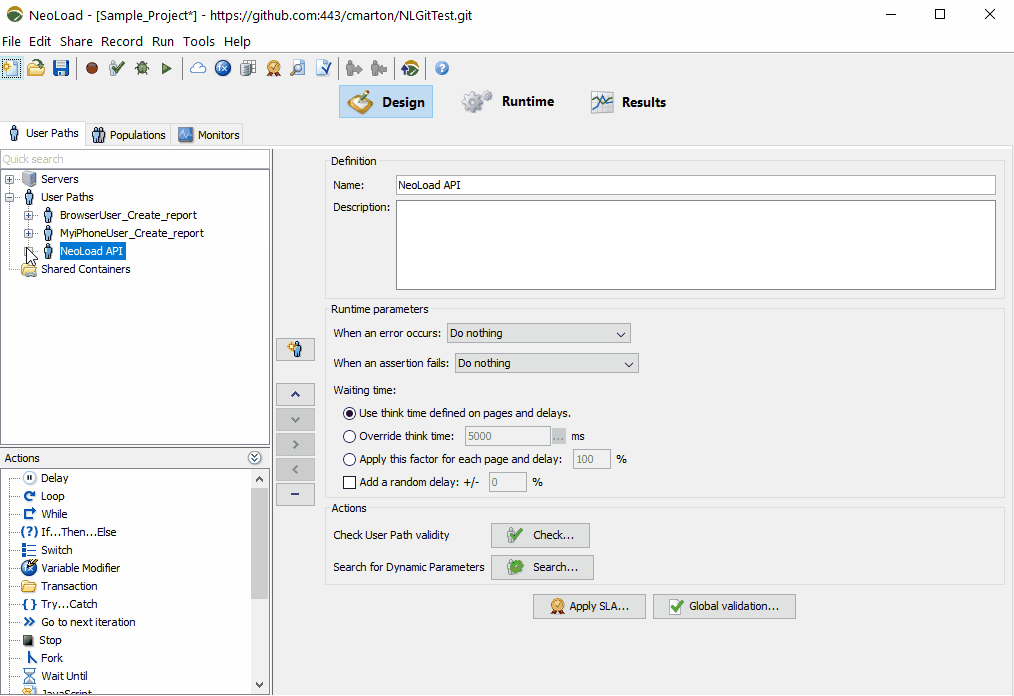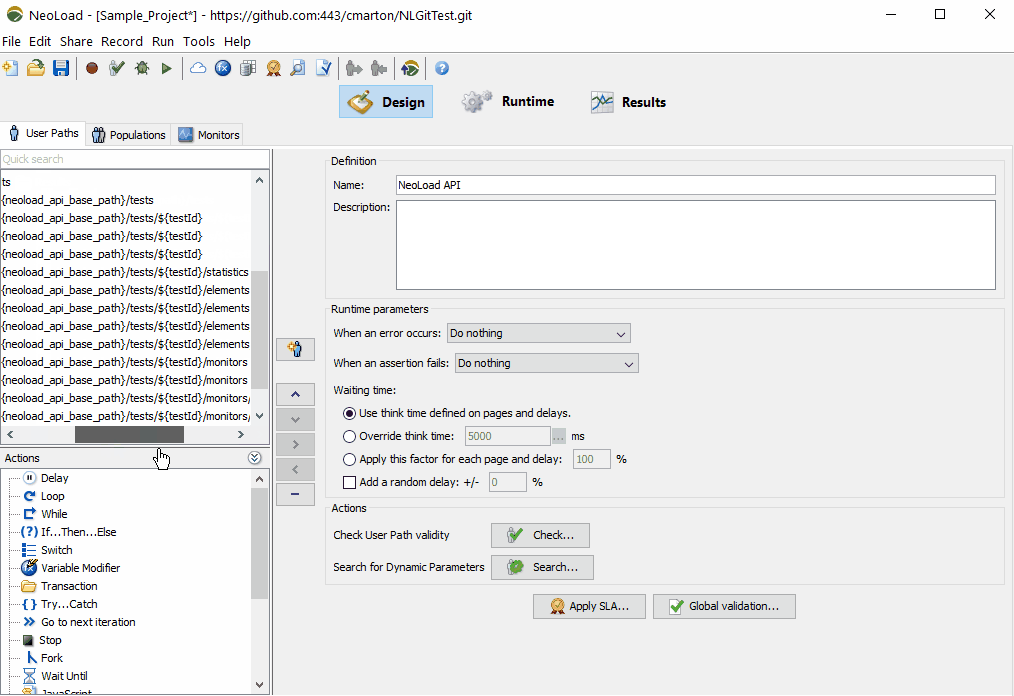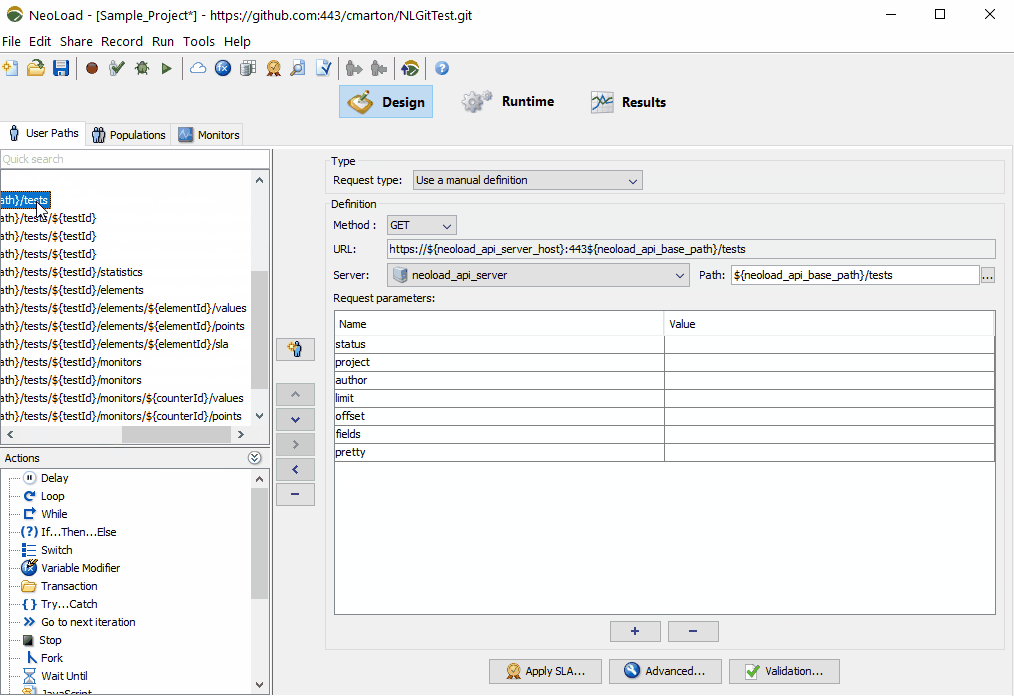
Easily import Swagger and any OpenAPI file to quickly get a NeoLoad performance test scenario which matches the API definitions.
Easy infrastructure
There is this “big rock” that load testing puts in the way of people who need reliable, statistically significant feedback on system or component performance. It is that the infrastructure you’re testing, the system under test (SuT), must be separate from the infrastructure used to put pressure on that SuT. With short, tiny local performance checks, using a single compute resource is fine.
With larger and longer tests, you have to break the work up across multiple compute resources. This is what we call “load generators.” Where you have more than one compute resource, you need a test orchestrator, which is what we call a “controller.” This is the same concept as CI systems and their build nodes, just for the purposes of providing performance data that is not biased by the SuT compute resources when under pressure.
In a pipeline, it’s a pretty bad idea to conflate the role of the build node with the load-making software, particularly because if that resource is stressed by making the load, it stops reliably reporting build status back to the CI master. Most build nodes are simply for tools such as Maven, Python, Sonar, and various CLIs. A flaky agent is a bad actor, particularly at scale when running many of these tests independent of one another. No one likes flaky or failed builds.
An alternative to this is to leave the pipeline’s worker node to just execution semantics, but requisition load infrastructure dynamically from a separate system. Early industry attempts to provide “sidecar” build containers to pipeline code ultimately collapsed under the complexities of container networking orchestration and resource contention. Still, some NeoLoad customers who adopted performance testing into pipelines as early as Jenkins 2.x would use cloud CLI tools like AWS or GCP to make provisioning calls, wait for acquisition, run load tests using the resources, then spin them down. That’s a lot of work and ultimately bulks out your pipeline code.
Particularly as many organizations now use cloud providers for their CI processes, NeoLoad Web Runtime supports auto-provisioning these resources via OpenShift and Kubernetes providers. Traditional static infrastructure is still supported by attaching these always-on resources to NeoLoad Web Resource “zones,” but if at all possible, most customers prefer provisioning as-needed testing infrastructure via elastic compute like AWS EKS Fargate and other Kubernetes-compliant container provisioning platforms. And if you don’t want to think about infrastructure, there’s always the NeoLoad Cloud Platform for SaaS-based load generators.
Abstracting load infrastructure from performance pipeline semantics has dramatically improved our customers’ ability to provide a self-service performance feedback model to many product teams across large organizations. Plus, it makes your pipelines far more concise, easy to understand, and quick to adjust as necessary.
Easy go/no-gos
We make all these things easy . . . so what? What’s the point of testing if it doesn’t quickly provide developers and ops engineers useful feedback that can actually help them do something about the performance of their systems?
Aside from the usual (but still necessary) raw load testing results, teams often set up thresholds or SLAs to warn when performance is outside an acceptable range. SREs tend to establish these thresholds using service level objectives (SLOs) and measure them with service level indicators (SLIs) so that it’s easy to know when performance takes a dive.
You shouldn’t have to wait a long time to know if during your performance pipeline, your systems aren’t ready and are failing performance thresholds. Going back to the notions of USE and RED, these service “impact” metrics should also be a critical part of your threshold and performance test failure strategy. The combination of RED and USE measurements during a load test allows performance pipelines to “fail fast” across both the pressure/load and impact/service observations. Without both these types of metrics, you simply do not have a sufficient view to know if performance is acceptable or not.
For this very purpose, the NeoLoad CLI used in our customers’ performance pipelines supports easy to implement “fastfail“ syntax. Similarly, our YAML-based “as-code” specification supports not only SLA thresholds (which may be different per environment and easy to define differently per environment), but also direct Dynatrace support to capture and emit the full spectrum of RED and USE metrics in NeoLoad Web results and dashboards.
Finally, comparing current tests to a baseline and accessing trend-based data should be easy within the context of pipelines. Using this data in real time via REST APIs is a key goal of the NeoLoad Web API, such that whatever your particular design and analysis requirements, you have a reliable and future-proof way of building these into your performance pipeline process.
Putting it all together
We at Tricentis help customers do these things on a daily basis, and there are so many configurations and technology choices already in play. Reference examples are available on GitHub, as are our load testing containerized components, but the broader performance testing learnings are:
- Start codifying your performance testing process over APIs.
- Use those patterns and learnings to extend out to other types of app testing.
- Don’t expect good results from heavy tooling baked into CI build nodes.
- Make sure that there are environment-appropriate thresholds/SLAs in place.
- Expose both RED and USE metrics into your pipelines to simplify go/no-go outcomes.
- Standardize how results are reported into a central place where data can be aggregated.
For an in-depth discussion of these performance testing topics, check out our white paper A practical guide to continuous performance testing.