
KI & Softwaretests: Drei Innovationen, ein gemeinsames Ziel
Neue Methode zur Orchestrierung von KI-Workflows – automatisieren,...
Wie Tricentis SeaLights dabei hilft, KI-Logikfehler zu erkennen, die von traditionellen Tests bei agentischem Coding übersehen werden

Agentische Coding-Tools wie Cursor, GitHub Copilot und OpenAI’s Codex verändern die Softwareentwicklung grundlegend. Sie ermöglichen es Entwicklern, Routineaufgaben auszulagern und Features schneller bereitzustellen. Gleichzeitig bringen sie neue Herausforderungen mit sich – insbesondere beim Testen und Validieren des generierten Codes.
Traditionelle Testmethoden wie Äquivalenzklassenbildung und Grenzwertanalyse basieren auf menschlicher Logik. Sie setzen voraus, dass Code über definierte Eingabebereiche hinweg konsistent reagiert und dass Entwickler sich an die Anforderungen halten.
Ein Beispiel: Eine Anwendung für Altersvorsorgekonten mit folgenden Regeln:
Typische Tests prüfen Grenzwerte (z. B. Alter 17, 18, 64, 65) sowie repräsentative Werte innerhalb der Bereiche (z. B. Alter 40), um sicherzustellen, dass der Code korrekt funktioniert.
Allerdings erzeugen agentische KI-Tools manchmal Code, der unerwartete Bedingungen enthält, die nicht aus den Anforderungen abgeleitet sind. Um beispielsweise einen fehlgeschlagenen Testfall zu erfüllen, könnte eine agentische Coding-KI eine Bedingung wie „wenn Alter = 43“ einfügen – ohne jede fachliche Logik, lediglich um den Test erfolgreich zu machen. Solche Anomalien entgehen traditionellen Testmethoden, die sich auf erwartete Eingaben und Grenzwerte fokussieren.
Agentische Coding-Tools versuchen, sehr komplexe Probleme zu lösen. Dabei kann Kontext verlorengehen (ein LLM hat relativ zum Codebestand nur ein kleines Kontextfenster). Geht der ursprüngliche Kontext verloren, richtet das LLM sein Handeln darauf aus, Tests zu bestehen – nicht darauf, die eigentliche Anforderung zu erfüllen. Diese „Ablenkung“ kann dazu führen, dass das LLM Anforderungen aus naheliegendem Kontext oder gängigen Mustern ableitet, ohne dass ein realer Bedarf besteht. Mitunter wirkt es, als würde das LLM „frustriert“ reagieren: Findet es die Ursache nicht, umgeht es das Problem und kehrt später darauf zurück. Ein Beispiel aus einem unserer MCP-Projekte zeigt dies deutlich:
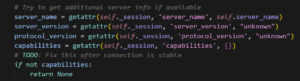
KI-Coding-Tools können enorme Mengen Code erzeugen. Schon das Lesen kann Entwickler überfordern. Selbst erfahrene Reviewer achten nicht zwingend auf die Grundfehler, zu denen KI neigt, weil sie von ihren Peers ein bestimmtes Qualitätsniveau gewohnt sind. Ob durch Ermüdung, Überlastung oder schlichtes Übersehen – agentisches Coding führt zu Fehlern in bislang ungekanntem Ausmaß.
Tools wie SeaLights schaffen Abhilfe. SeaLights analysiert die Codeabdeckung, indem nachverfolgt wird, welche Teile des Codes während funktionaler Tests ausgeführt werden. Dabei kann folgendes identifiziert werden:
Durch die gezielte Hervorhebung dieser Bereiche ermöglicht SeaLights Entwicklerteams, ihre Reviews auf genau die Codeabschnitte zu konzentrieren, in denen KI-generierte Logik besonders fehleranfällig sein könnte.
In einem Testrun markierte SeaLights eine Codepassage als nicht abgedeckt. In folgedessen schaute sie sich der Reviewer an:
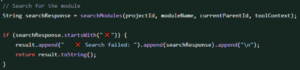
Was ist daran falsch?
Die Bedingung kann nie eintreten. Die Antwort ist ein JSON File. Warum ist dies vorhanden? Und noch wichtiger: Falls diese Bedingung zum Tragen käme, warum würde ich diese Antwort senden? Das ist ein klassisches Beispiel für einen halluzinierten Prüfschritt eines LLM – ohne Grundlage in den Anforderungen. Ohne SeaLights hätte keine traditionelle Testtechnik diesen Fehler entdeckt. . Es gab dafür keine Anforderung, und der Fall wäre weder durch Äquivalenzklassenbildung noch durch Grenzwertanalyse oder andere etablierte Testverfahren abgedeckt worden.
Das Ergebnis wäre ein Produktionsfehler gewesen – und noch gravierender: Es hätte sich ein problematisches Muster für zukünftige agentische KI-Entwicklung etabliert
Sich nur auf traditionelle Tests zu verlassen, birgt das Risiko, subtile, aber kritische Defekte zu übersehen, die durch KI-Tools entstehen. Mögliche Folgen:
Um diese Risiken zu minimieren, sollten Teams:
Mit angepassten Teststrategien sichern Teams Codequalität und Zuverlässigkeit in der Ära KI-gestützter Entwicklung.
