
AI-powered but not autonomous yet: How artificial intelligence can address three common UI testing challenges
Learn how AI can be used to eliminate common testing headaches, as...
How Tricentis SeaLights helps catch AI logic bugs missed by traditional tests in agentic coding

Agentic coding tools like Cursor, GitHub Copilot, and OpenAI’s Codex are reshaping how software is developed. They enable developers to offload routine tasks and accelerate feature delivery. However, these tools also introduce new challenges – particularly in how we test and validate the code they produce.
Traditional testing techniques, such as equivalence partitioning and boundary value analysis, are designed around human logic. They assume that code will behave consistently across defined input ranges and that developers will write code aligned with specified requirements.
For example, consider a retirement account application with the following rules:
A typical testing strategy would involve checking boundary values (e.g., ages 17, 18, 64, 65) and representative values within each partition (e.g., age 40) to ensure correct behavior across defined ranges.
However, agentic AI tools sometimes generate code that includes unexpected conditions not derived from the requirements. For instance, to satisfy a failing test case, an agentic coding AI might insert a condition like “if age = 43” without any logical basis, simply to make the test pass. Such anomalies are not easily caught by traditional testing methods, which focus on expected input partitions and boundary conditions.
Agentic coding tools are doing their best to solve very complex problems with large problem spaces. Along the way, context can be lost (the LLM only has a small context window relative to the codebase). Once the original context is lost, the LLM will focus on making the test pass, not on the original requirement. This “distraction” can also lead to the LLM “imagining” requirements based on nearby context or common patterns rather than concrete need.
Finally, we have noticed that LLMs can become “frustrated.” If it cannot find the root cause, it might just “work around it” and try to come back to it later. Below is a great example from one of our MCP projects:
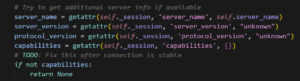
AI coding tools can generate huge amounts of code. Developers are often incredibly stretched just to read the code, and can become overwhelmed easily. Experienced peer reviewers also may not be looking for the basic kind of error that AI can make, because they are used to a certain level of completeness from their peers.
Whether it is from exhaustion, mental overload or simply just missing it, Agentic Coding can introduce these errors, and does introduce these errors at a rate far beyond what we have seen to date.
To address these challenges, tools like SeaLights can be instrumental. SeaLights performs code coverage analysis by tracing which parts of the code are executed during functional tests. This process helps identify:
By highlighting these areas, SeaLights enables engineers to focus their review efforts on code segments that may harbor defects introduced by AI-generated logic.
During one of our test runs, SeaLights highlighted that this code was not covered, the reviewer picked it up and had a look…
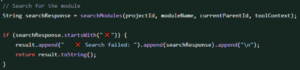
So what’s wrong with that?
The problem is, that condition could never happen. The response is a JSON file. So why is that there? What does it add? And more importantly, If that condition got exercised, why on earth would I send that response? This is a classical example of an LLM hallucinating a check that was not in the requirement, for reasons known only to the big ball of math in the cloud. Without SeaLights, no traditional testing technique would have caught this bug. There was no requirement for it, and it would not be covered by equivalence partitioning, boundary value analysis or any other nominal testing technique. This would have created a defect in production, and worse yet, established a pattern for future agentic AI coding, that this is how we respond to errors.
Relying solely on traditional testing techniques may result in overlooking subtle yet critical defects introduced by AI coding tools. These defects can lead to:
To mitigate these risks, development teams should consider:
By adapting testing strategies to account for the unique behaviors of agentic coding tools, teams can maintain code quality and reliability in the evolving landscape of AI-assisted development.

