
Agentic Test Automation in action
AI-powered testing assistant purpose-built for Tosca to enable...
How a robust and flexible solution for data validation and reconciliation supports decision integrity.
Editor’s note: Wayne Yaddow is an independent consultant with over 20 years’ experience leading data migration/integration/ETL testing projects at organizations including J.P. Morgan Chase, Credit Suisse, Standard and Poor’s, AIG, Oppenheimer Funds, IBM, and Achieve3000. Additionally, Wayne has taught IIST (International Institute of Software Testing) courses on data warehouse, ETL, and data integration testing. He continues to lead numerous ETL testing and coaching projects on a consulting basis. You can contact him at wyaddow@gmail.com.
European Union (EU) law requires that all financial firms conduct regular reconciliations of their front office records against financial databases and data integrations reported to EU regulators.
Due to the EU obligations under MiFID II, (i.e., the EU Markets in Financial Instruments Directive 2004), significant data risk is inherent in the process of data integration and reporting that could result in possible loss of BI “decision integrity”. All firms must implement a robust and flexible solution for data validation and reconciliation. MiFID II covers nearly the entire universe of financial instruments.
Data risk is an increasing problem in the financial industry due to the number of processes data is exposed to between its source and its target destinations. Under MiFID II, reporting data may need to pass through a number of external firm’s databases before reaching regulators. Each step frequently includes both manual and automated data transformation and enrichment layers, potentially introducing errors.
The further removed a transaction is from its final target, the greater the likelihood that errors will occur. It also becomes increasingly difficult to track these errors and reconcile data back to data sources (i.e., data lineage). The consequence is higher costs through manual data reconciliations, and the potential for enquiries and penalties due to inadequate controls.
Data reconciliation processes and tools are used to during testing phases during a data integration where the target data is compared against original and ongoing transformed source data to ensure that the integration (e.g., ETL) architecture has moved and/or transformed data correctly. [3]
Broadly speaking, data reconciliation is an action of:
Data reconciliation is central to achieving those goals. The stepped-up pace of the market and more demanding client expectations have made a high quality data reconciliation and data lineage assessment process a competitive necessity.
Candidate applications for data reconciliation can be based on these influences:
Data lineage processes and tools help organizations understand where all data originated from, how it gets from point to point, how it is changed/transformed, and where it may be at any time. [3]
Through data lineage, organizations can understand what happens to data as it travels through various pipelines (e.g., spreadsheets, files, tables, views, ETL processes, reports); as a result, more informed business decisions ensue. Data lineage clarifies the paths from database tables, through ETL processes, to all the reports that depend on the data; data lineage enables you to double-check all reports to ensure they have everything required.
Data lineage enables organizations to trace sources of specific business data for the purposes of tracking errors, implementing changes in processes, and implementing system integrations to save substantial amounts of time and resources, thereby tremendously improving BI efficiency and “decision integrity”. And, without data lineage, data stewards will be unable to perform the root cause analysis necessary to identify and resolve data quality issues.
Organizations can not advance without understanding the story of that data that it uses continuously for decision making integrity. Data lineage gives visibility while greatly simplifying the ability to trace errors back to the root cause in a data analytics process.[3]
Finally, data lineage is often represented visually to reveal the data flow/movement from its source to destination via various changes. Also, how data is transformed along the way, how the representation and parameters change, and how the data splits or converges after each ETL or incorporation into reports.
Generally, data reconciliation for information systems is an action of:
Example: Data warehouse ETL’s integrate product data from two sources: “Source A” and “Source B” (Figure 2), Each Source A and B record may have a different product number (Prod_num) for the same product name (ex., Mutual Fund A). [1]
In the image below, ETL’s create the “Data Warehouse” tables that allow for only one product number (Prod_num) per product. In case of a data discrepancy, the value from Source A will have precedence over the value from Source B.
Due to these implemented business rules, the Data Warehouse tables and BI reports will contain the Prod_num for product (Product: Mutual Fund A, Prod_num: 123) the same as in Source A, while the Prod_num from Source B will be logged as an exception – perhaps to be corrected in the future.
In Figure 1, the reconciliation of data between the Data Warehouse and the Source B Exceptions Log will be compared:
Note: If Product_num exceptions in Source B had not been captured and logged, Data Warehouse Prod_nums and BI reports would not all reconcile with those from Source A.
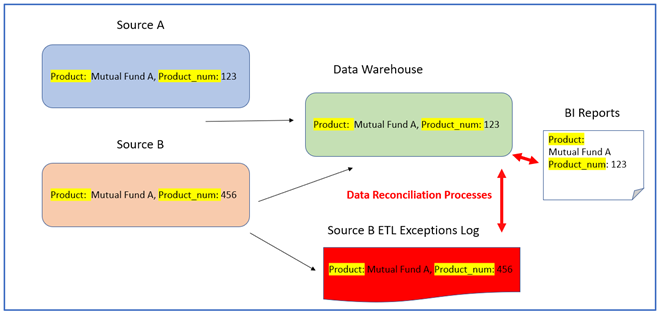
Example of Data Reconciliation flow for a sample ETL integration
In this example the reconciliation processes are concerned with the data in the final reports, together with all the ETL exceptions, are accurately reconcilable with the Prod_nums in the original Source A.
A few challenges prevent widespread deployment of data reconciliation systems include a lack of services for a) securely and accurately generating data reconciliation information within a computing system, b) securely coordinating that collection within distributed systems, and c) understanding and controlling the storage and computational overheads of managing such
processes.
Next up: “Setting Up Data Warehouse/BI Projects to Support Data Reconciliation”
[1] Rachid Mousine, “Design Essentials for Reconciliation Data Warehouse”, Formation Data Pty Ltd.
[2] “Running the Vital Checks Database Wizard”, https://documentation.tricentis.com/tosca/1220/en/content/tosca_bi/bi_vital_filetodb.htm Tricentis.com
[3] Wikipedia, “Data Lineage”, “Data Validation and Reconciliation”, Wikipedia.org
AI-powered testing assistant purpose-built for Tosca to enable...

We’re extending our proven expertise in test automation with...
Learn how to build a Workday testing strategy that minimizes...
Connect NeoLoad with Datadog to unlock real-time observability and...
Learn how a top European bank drove Agile transformation, tackled...