
Reports & White Papers
Tricentis qTest cloud security
This white paper highlights the safeguards leveraged to protect...
An incident report is a document that captures information about a specific incident, unexpected event, accident, or near miss.

CrowdStrike unintentionally sent a flawed configuration update (Channel File 291) to its Falcon Windows sensors on July 19, 2024. This update resulted in Blue Screens of Death (BSODs), memory crashes, and boot loops on approximately 8.5 million systems worldwide across various sectors. The root cause, according to the official incident report released by CrowdStrike, was a validation failure in their content deployment process.
Although this outage lasted only about 78 minutes, it cost US Fortune 500 companies approximately $5.4 billion and triggered a global IT backlash from the public, companies, and Congress. It also revealed that the CrowdStrike team needed to review its deployment process. As a result, they have implemented tightened testing protocols, adopted phased rollouts to limit potential impact, and introduced additional validation measures to catch errors earlier.
This incident, for starters, demonstrated the importance of incident reports. They’re not just paperwork; they help your teams and shareholders understand what happened, why it happened, and how they can prevent the incident from happening again. These reports also help companies, regardless of their size, engage in regular tabletop exercises and strive for true disaster recovery.
However, as important as they are, how to document one isn’t always obvious for various teams. But what exactly is an incident report? When should you write one? What should it include? And how do you make it more than just a checkbox exercise, but rather one that will actually be helpful to your team’s growth and resilience in the long run? This post answers all those questions and more.
An incident report is a document that captures information about a specific incident, unexpected event, accident, or near miss.
An incident report is a document that captures information about a specific incident, unexpected event, accident, or near miss. The aim is to help the team identify the core issues, assess risks, ensure accountability, and develop preventive measures to prevent a similar incident from occurring again.

While the concept of an incident report applies to various industries, in the IT and software development space, these reports play a critical role due to the fast-paced nature of the ecosystem. Systems fail, bugs can slip through development, and deployments often go wrong.
Incident reports serve as learning moments within teams, improving system reliability, identifying patterns over time, and ensuring that the same incident does not recur.
For an incident report to be impactful, it must be structured, factual, and comprehensive. A good example of an incident report is the GitHub availability report for October 2023, which describes the two incidents that resulted in degraded performance across GitHub services.
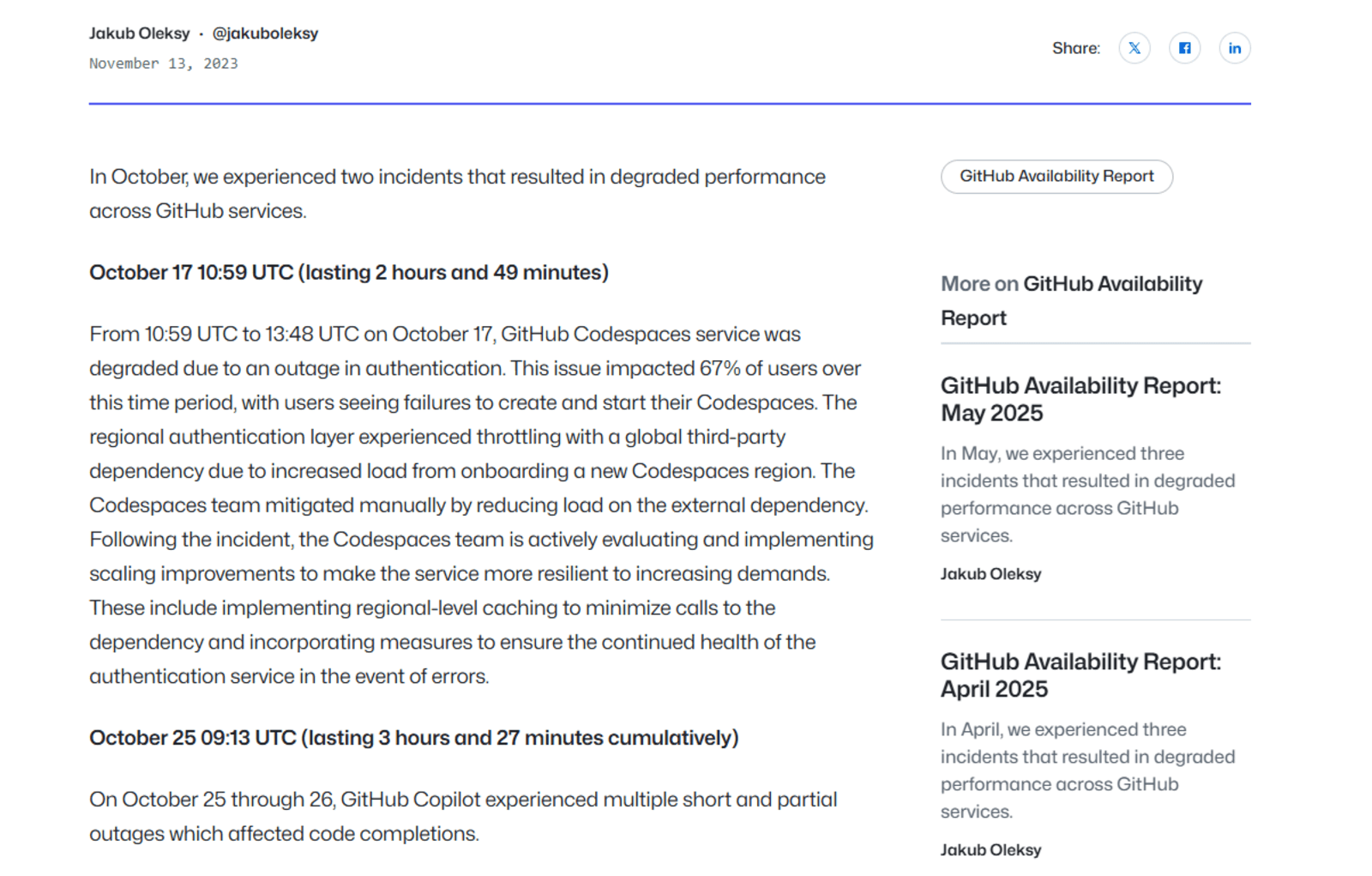
Just like the GitHub report, a good incident report should include the following:
Incident reports are primarily used whenever an unplanned disruption occurs that interrupts normal operations or poses a risk. These disruptions can include system outages, downtime, security incidents, third-party or infrastructure failures, and performance degradation.
However, depending on the organization, incident reports are created even for “near misses” or low-severity incidents—for example, customer-relevant incidents.
Below are some key benefits of incident reporting:
Since incident reports can serve as a learning moment, documenting the actions taken during an incident can clarify who did what and when. It also reinforces correct responses or highlights mistakes, and it ensures repeatability for similar future incidents.
It serves as a centralized record that helps the teams inform themselves about risks, failures, or vulnerabilities across departments. This prevents knowledge from being isolated.
Every incident can be treated as a feedback loop or a chance to improve.
Every incident can be treated as a feedback loop or a chance to improve. Thus, these reports can help you identify gaps, spot manual steps that can be automated, and fix any potential bottlenecks.
Well-written incident reports can serve as documented institutional memory. Since they capture technical context that might otherwise be forgotten, they can serve as case studies for training new developers or site reliability engineers (SREs).
Over time, incident data can reveal patterns such as bottlenecks, frequent root causes, potential risks, and high-risk systems. These reports also contribute to metrics such as mean time to resolve (MTTR), mean time to detect (MTTD), and incident frequency, which can provide insight into your technical debt and justify investments in infrastructure, tooling, or automation.
A well-written incident report shows that the team takes responsibility (ownership) and is open to sharing details of the incident, especially for public-facing incidents. It also demonstrates an openness to learning and builds credibility with developers and enterprise clients alike. As JJ Tang noted, when they faced an outage, “Facebook deserves a lot of credit for how transparent it was about the incident.” This is because, while Facebook’s October 2021 outage can be described as SREs’ nightmares, it was also a pretty big learning opportunity for SREs in other tech companies.
For organizations operating under regulatory frameworks (SOC 2, GDPR, ISO 27001), incident reporting demonstrates that they are following due diligence and are prepared for a response. These reports also serve as good audit trail documentation.
A well-written incident report can be your team’s secret weapon. But how do you craft one that’s both thorough and actionable?
Speak with everyone involved and determine the “who, what, when, and where” of the incident. For more critical issues, such as unauthorized access or data breaches, specify the data that was breached, how it occurred, and the potential impact.
This is where you describe the incident clearly and in detail, without any vague language. You should include error messages, logs, and any actions taken to resolve the issue.
Specify what and who was impacted to gain an understanding of the incident’s scope and determine the necessary communication and recovery paths.
Create a step-by-step sequence of key events from when the issue was identified to when it was resolved.
Detail the steps and actions taken to resolve the incident.
Dive deeper. What was the root cause (or suspected cause)? Was it a human error or a failed dependency? Did it affect another service? Were there any security complications? Has this happened before?
Once you have a comprehensive overview, write the report.
You need to be clear on what needs to be done to ensure it doesn’t happen again, and if it does, how to resolve it faster and with less cost.
You need to be clear on what needs to be done to ensure it doesn’t happen again, and if it does, how to resolve it faster and with less cost. This could be automated checks, monitoring, runbook updates, or, as in CrowdStrike’s example, additional validation measures.

At the end of the day, as stated in the GitLab’s incident report section of the handbook “The primary goals of writing an Incident Review are to ensure that the incident is documented, that all contributing root cause(s) are well understood, and, especially, that effective preventive actions are put in place to reduce the likelihood and/or impact of recurrence.”
The responsibility for writing an incident report lies with the individual or team most knowledgeable about the incident in question. However, while it may be written by one person, input from various teams, units, or departments is often required, as collaboration is typically necessary in high-severity incidents.
Thus, input often would be required from the first responder (who detected the incident), the incident commander (who was assigned to lead the response), the SRE/DevOps team, the security team, and the compliance team. The number of people involved may vary depending on the incident, organization, and severity of the event.
Yes, and it actually should be. Working with a standardized incident report template assures that every critical detail is captured in the report. That means that every report released is consistent, clear, and complete across all incidents, regardless of who’s writing the report.
Besides maintaining consistency, a template reduces ambiguity and promotes cross-team communication. Various tools make this process simpler. For example, Tricentis qTest ensures that you can link test results, user stories, and defects directly to incident records. This enables faster root cause analysis and better traceability.
To achieve better results, consider pairing these tools with automation and integrated testing platforms. A Forrester study (commissioned by IBM), further quoted by Squadcast, showed that organizations leveraging AIOps and advanced observability tools experienced a 50% reduction in mean time to repair (MTTR) and a 50% decrease in the number of severe incidents.
Erin Doyle, a founding engineer at Quotient, once said after experiencing one of the worst incidents of her career, “After resolution, a blameless post-mortem process can unearth valuable insights. It certainly helped us…..Here again is an opportunity to provide pragmatic leadership, facilitating robust conversation without judgment, and orienting solutions based on a thorough root cause analysis.” So, how your team responds, documents, and decides to learn from them is what defines operational maturity.
Incidents are inevitable in modern software delivery. It’s important always to see them as an opportunity to turn chaos into clarity and learn from it with effective incident reports. To get even more out of incident reporting, consider using a monitoring tool to help you identify issues faster. Try out a Tricentis free trial today!
This post was written by Ifeanyi Benedict Iheagwara. Ifeanyi is a data analyst and Power Platform developer who is passionate about technical writing, contributing to open-source organizations, and building communities. Ifeanyi writes about machine learning, data science, and DevOps, and enjoys contributing to open-source projects and the global ecosystem in any capacity.

Learn how to supercharge your quality engineering journey with our advanced testing solutions.
Learn how to supercharge your quality engineering journey with our advanced testing solutions.